
在當今的資訊時代,一個主動式且高效的資訊維運系統對於確保系統運行的穩定性至關重要。
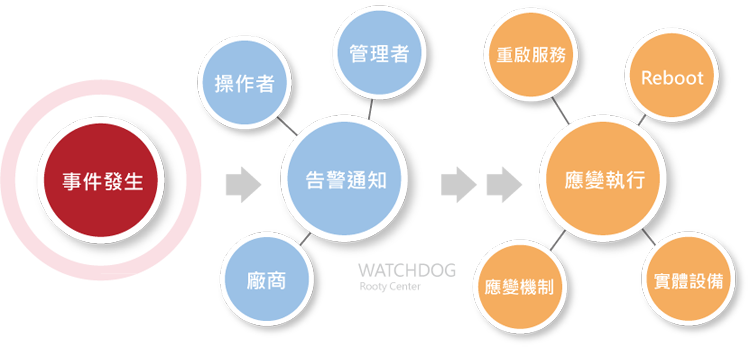
WATCHDOG系統能夠即時偵測並對異常狀態進行自動化告警,讓維運團隊能夠迅速做出反應。
本節將從多個角度深入探討WATCHDOG系統告警功能的設計理念及實施細節,
表達我們的設計團隊如何綜合考慮各種因素,確保系統的設計理念符合當前環境。
異常狀態的定義
首先,我們需要界定何謂「異常狀態」。這包括了從數據、字串內容到事件觸發等多種資料基準點的檢測。
告警臨界值的設定
告警事件的觸發完全依據於是否符合預設的「告警臨界值」。這要求我們事先明確定義這些臨界值,以及當達到這些臨界點時的處置方案。
監控目標的建立
有效的告警機制起始於清晰的監控目標設定,包括:
➢ 需要監控的項目
➢ 定義監控項目的異常臨界點,舉最常出現的類型,如:
➥數據類:使用大於【>】或小於【<】來界定「告警臨界值」
➥文字類與訊息類:透過字串比對和邏輯運算來確認是否觸發警報
➥事件觸發類:接收到特定訊息後立即發出警報
其他通報需考量要點
➢ 警報的效率、嚴緊度與敏感度評估
➢ 警報的傳遞管道與通知名單設定
➢ 警報後的緊急處置方案
➢ 建立重要的關聯整合點,如封包測試的佈線追蹤
➢ 與監控相關的資訊建立,包括設備位置、用途、保管人及維護廠商等
嚴緊與靈活的異常檢測機制
在維護一個高效能的資訊維運系統中,掌握合適的告警平衡至關重要。
過多無關緊要的告警會導致維運團隊對真正重要的警報視而不見,就如同放羊小孩一樣。
為了避免這種情況,我們需要一套既嚴謹又靈活的異常檢測機制來精準地識別並處理真正的問題。
以下是我們在設計WATCHDOG時,設計的策略概念
精細化異常檢測規則
當偵測系統要判斷是否為異常事件時,必須要有三項以上的條件才可發出警報,
同時必須依每一類型的設備特性與使用重要性分別設定。
➢ 符合單項功能使用的數據
➢ 連續多次的重復檢測
➢ 異常後重復檢測的延遲時間,用以降低過敏反應
➢ 特定時段內不發布告警通知,避免非關鍵時刻的干擾
➢ 根據每一項監控目標細節定義特定的告警值
不是每一個監控項目的警報條件與告警臨界值都是一樣
縱然是相同的資訊設備,相同的監控項目,
仍然必須依資訊設備與監控項目的系統特性或使用特性定義告警臨界值與告警後的處置。
➢ 每個監控細項都提供獨立的告警檢測條件和告警臨界值,包括數據、字串、事件觸發等因素
➢ 設定重測的延遲時間和次數,針對特定時段可以進一步設定時間區間條件
➢ 為每個監控細項設定獨立的通報群組和連動警報後續處理機制
如:發出告警後自動對該設備下達命令
提升效率與知識傳承
自動化的告警檢測機制對於系統負責人或維運人員來說,提供了巨大的幫助。它不僅節省了大量檢查系統狀態的時間,
但更重要的是,如何降建立起來的警報規範傳或制度承下去。
➢ 一個經過考驗的告警檢測條件,涵蓋了各種狀態訊息與數據,若能將系統負載、數據異常的標準值與經驗整合於標準規範中,將極大地促進知識的傳承與應用。
➢ 在設定告警臨界值時,應從系統健康檢查開始,以了解系統運行的狀態,從而精準修正告警值。
➢ 避免僅依賴單一條件觸發告警,除非是在特定情況下,例如告警轉送或代理告警通知。
告警檢測的策略案例
➢ 單一條件值的告警檢測
若監控系統僅依據單一條件進行告警,如CPU負載超過80%即發出警報,可能導致大量的無效告警。特別是在高負載作業,
如備份期間,告警訊息可能會不斷出現,造成干擾。
➢ 多重條件值的告警檢測
若採用多重條件進行告警檢測,如CPU負載超過80%、連續三次檢測仍超過負載、且每次重測間隔5分鐘,僅在這些條件同時滿足時才發出告警。
加上可以設定特定時段不發出告警,就可以減少不必要的干擾。
➢ 依據系統使用特性和環境調整告警條件
可以更精確地識別真正的系統問題,強調告警設定需要考慮系統的實際運行狀態和特性,而非僅依賴於單一數據點。
例如,兩台伺服主機中,一台CPU負載95%,另一台負載12%,哪台有問題?
CPU負載率高達95%可能看似有問題所在,
但安裝後使用都很正常從未出現過當機現象或過慢的狀況,而另一台是平時負載68%,突降至12%,
如果是因為某些服務停止而讓CPU負載率從68%下降為12%,那是哪一台主機有問題?
規劃週詳的通報群組
對於【通報名單】的設定,要有能力應付不同的【設備群組】與【負責群組】甚至【特定群組】,
包含了系統負責人或維運人員與維護廠商、資訊中心主管等。
其他通報群組設計考量的要點如下:
事件發生與解除通報
根據事先設定的通報名單,當告警事件發生或解除時,系統會可依照使用者設定的通報群組,自動通知系統負責人、維運人員、維護廠商,以及專業技術工程師。
多樣化通報群組設定
通報名單需能應對不同設備群組、負責群組,甚至特定群組的需求,包括系統負責人、維運人員、維護廠商和資訊中心主管等,每個通報群組應能建立超過30筆名單,以針對不同警報事件設定專屬通報對象。
靈活的告警條件與通報方式
在各監控項目的告警條件下,指定特定通報群組,並根據群組特性,選擇適合的通報管道,如簡訊、電子郵件等,以發佈告警訊息並可額外延伸啟動連動控制命令。
細化通報群組選擇
通報群組名單可細分至單一監控項目,如同一伺服器的不同硬碟使用率或CPU負載率可分配至不同的通報群組,確保告警訊息的精確發送。
告警訊息發佈策略
告警訊息會根據監控項目的具體細節選擇通報群組名單,並按照設定的優先順序,從最具體的監控項目到整體共用名單,避免重複發佈告警訊息。
通報群組類別劃分
通報群組名單按照不同的類別進行劃分,如依監控項目、設備主體、特定群組、系統與設備、系統開機、定時簡訊測試、整體共用名單等,以滿足各種監控需求。
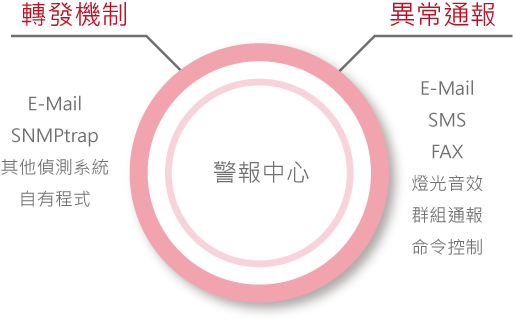
靈活定制的通報策略
WATCHDOG系統支持通過多種管道同時傳遞告警訊息,用戶可以根據實際需求設定告警發佈的方式,並能隨時更新通報群組的名單,以確保訊息的傳達。
結合控制命令的告警訊息,除了基本的告警通知,WATCHDOG還支持與控制類型功能的同步使用,如緊急或一鍵關機命令,適合透過音效廣播或警報燈具等方式進行。

告警訊息可透過以下管道發佈
➢ 即時資訊戰情中心的監控畫面展示
➢ 簡訊(SMS)發佈
➢ 郵件(Mail)發佈
➢ LINE訊息發佈
➢ Telegram訊息發佈
➢ 轉送 SNMP Trap
➢ 傳真(Fax)
➢ 音效廣播
➢ 數位控制(DO),如:警報燈、警報器、電源開關
➢ 網路開機
➢ 標記閘道(簡訊命令用)
➢ 訊息客屬介接整合
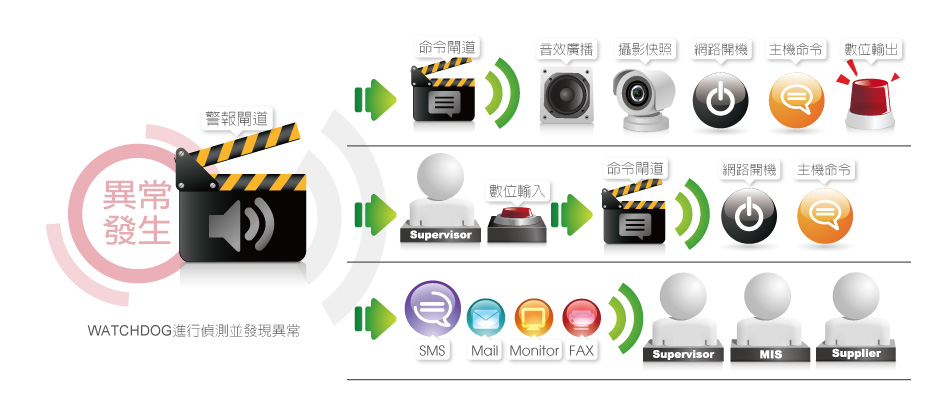
訊息介接整合
當使用單位己經有建立企業資訊入口系統(EIP)時,亦可依需要提供告警訊息整合於,
企業資訊入口系統(EIP)的推播系統或即時通訊系統,如: Line ,
如果有其他維運管理平台系統,同樣可經由雙方認可之資料協定提供告警資訊內容。
告警連帶串聯控制命令
當告警事件發生時,WATCHDOG除了通知維運人員、維護廠商或系統負責人外,還能設定專屬功能【命令閘道】,
將告警事件視為觸發後續控制機制的動作,透過【命令閘道】進行警報後續的控制。
每一個警報控制流程都能串聯控制多個命令閘道,從而對256台以上的伺服器下達各類型命令,包括系統指令、IPMI命令、CLI命令等,實現直接對伺服主機、特定設備的命令下達,或是控制電源設備和一鍵執行等操作。
若想了解更多關於【命令閘道】之功能,可查看文章 【命令閘道】
。